GPT-5.5 пробила 50% на бенчмарке OfficeQA - и это всё равно про пилот, а не про боевой режим
15 мая OpenAI и Databricks выпустили совместный анонс: GPT-5.5 стала первой моделью, которая прошла 50% точности на тесте OfficeQA Pro. Звучит как победа. Если разобрать цифры - это сигнал, что для работы с реальными корпоративными документами модели дозрели до пилотного проекта, но не до полностью автоматической работы. Расскажем, что на самом деле померили и кому это полезно знать.
Что было до#
GPT-5.5 вышла 23 апреля 2026 года. Это последняя топ-модель OpenAI. Она заточена под задачи, где нейросеть сама планирует шаги, дёргает внешние инструменты, пишет код, открывает страницы в браузере. Эти задачи в индустрии называют агентскими. По цене $5 за миллион входных слов модели (токенов) и $30 за миллион выходных - в средней лиге топ-моделей. Окно памяти у API (программного доступа для разработчиков) - 1 миллион токенов, у среды Codex - 400 тысяч.
Параллельно, в марте 2026, Databricks опубликовала научную работу OfficeQA Pro: тест на чтение корпоративных документов. Это не "ещё один MMLU" (популярный тест на эрудицию), а попытка проверить модели на честно-сложной задаче: понять документ, найти нужное место, сложить числа, ничего не выдумать.
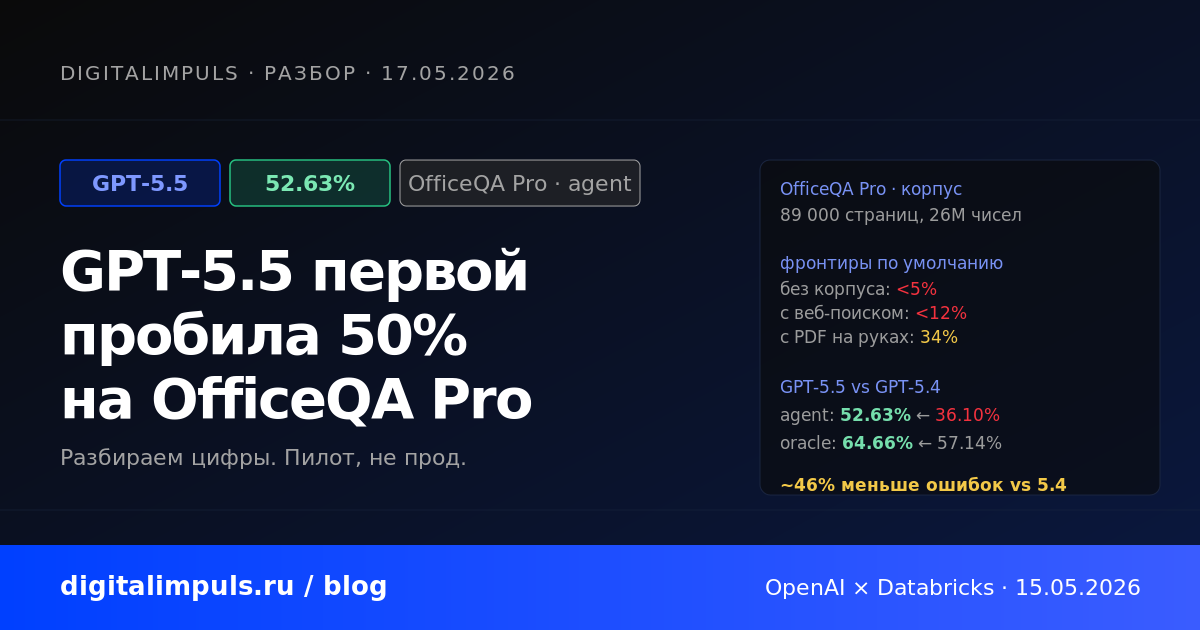
В тесте - бюллетени Казначейства США за почти 100 лет: 89 тысяч страниц, 26 миллионов цифр. К ним 133 вопроса вида "сколько составила определённая статья расходов в таком-то году и как изменилась с тех пор". Полная версия теста включает ещё 246 вопросов попроще.
Цифры на старте были отрезвляющие. Без доступа к документам топ-модели выдавали меньше 5% правильных ответов - просто выдумывали. С обычным поиском по сети - меньше 12%. Даже когда модели давали все документы на блюдечке, средняя точность была около 34%. Лидеры рынка - Claude Opus 4.6, GPT-5.4, Gemini 3.1 Pro - оказались примерно в одной лиге. Лига честно говорила: до автоматического агента-аналитика по корпоративным документам нам ещё далеко.
Что нового#
GPT-5.5 в режиме полного агента#
Главная цифра релиза - режим, который Databricks называет полным агентом. Это самый жёсткий замер: агенту дают только название архива документов, никаких готовых файлов и подсказок. Дальше он сам ищет нужные страницы, разбирает их, считает, проверяет ответ. На этом тесте GPT-5.5 набрала 52.63% против 36.10% у предыдущей GPT-5.4. Это снижение количества ошибок на 46% относительно прошлого поколения и первый случай, когда модель в этом режиме перешла половину.
Контекст для понимания: 52.63% значит, что почти каждый второй ответ всё ещё неправильный. Это не "автономный аналитик", это "честный стажёр со списком источников, за которым надо перепроверять". Но прогресс между двумя релизами в полгода реальный.
Режим, когда документы уже подсунули#
Второй замер - когда агенту сразу дают нужные документы и веб-поиск. Ему остаётся прочитать и посчитать. GPT-5.5 даёт 64.66%, GPT-5.4 - 57.14%. Прирост около 13%, новый рекорд на этом срезе.
Это режим, наиболее похожий на типичный путь в реальных проектах: документы нашли поиском заранее, модели остался разбор. И здесь видно, что разрыв с прошлым поколением меньше: на финальной интерпретации все топ-модели подбираются к потолку. Основной выигрыш GPT-5.5 - именно в способности самостоятельно собрать всю цепочку, а не в качестве "чтения".
Как это завернули в продукт#
В тот же день Databricks объявила доступ к GPT-5.5 через свой шлюз Unity AI Gateway. Шлюз делает три вещи разом: централизует учёт расходов, контроль доступа и логирование запросов. Сверху - инструменты AgentBricks и Agent Supervisor API: дирижёр, где GPT-5.5 разводит подзадачи между специализированными агентами (поиск, разбор, расчёт), а Databricks следит за тем, кто что делает и сколько это стоит.
Для крупных команд в США и Европе это закрывает важную дырку: до сих пор закатить топ-модель в банк или фарму было больно из-за требований к безопасности данных. Сейчас у клиента остаётся одна точка контроля - и можно работать с теми же документами, которые уже лежат в хранилище Databricks.
Где это применимо#
Команды, которые внедряют языковые модели поверх PDF-документов: договоры, отчётность, регламенты, ТЗ - всё это похоже на структуру OfficeQA. Если планируешь автоматизировать работу с такими файлами, тест - честная проверка реальностью: 50-65% точности в лучшем сценарии значит, что без человеческого контроля систему запускать нельзя. Закладывай проверку ответов и фильтр по уверенности модели в дизайн с первого дня.
Те, кто работает с табличными данными внутри документов: самые большие провалы у моделей были именно на стыке текста и таблиц. Нашёл цифру в неправильной колонке - получил неправильный ответ. GPT-5.5 здесь сильнее, но проблема не исчезла. Если в проекте нужно сопоставлять данные между разделами - тестируй на своём наборе документов, а не верь графикам из пресс-релиза.
Те, кто оценивает топ-модели для своего стека. Методика OfficeQA Pro открыта на GitHub. Можно собрать аналогичный тест на ваших документах: 100-200 вопросов с эталонными ответами, два режима (с готовыми PDF и без), прогнать все доступные модели. Это даёт честный ответ, нужна ли тебе именно GPT-5.5 или хватит более дешёвой модели с поиском по своим документам (метод RAG, retrieval-augmented generation).
Российские команды. Databricks в РФ напрямую недоступен из-за санкций. Но сам подход к оценке моделей применим: своя версия OfficeQA на своих документах, прогон через те модели, к которым есть доступ - Yandex GPT, GigaChat, проксированные OpenAI и Anthropic. Это полезнее, чем смотреть на чужие графики.
Что не очевидно#
Первое - конфликт интересов в публикации цифр. Тест делала Databricks, программу разбора документов - тоже Databricks (ai_parse_document даёт +16% прироста точности к средней). Партнёрский анонс с OpenAI и эффектные цифры GPT-5.5 удобно встают в маркетинг продукта Unity AI Gateway. Это не делает цифры неправдой, но честнее повторить замер на своих документах, прежде чем закладывать GPT-5.5 в боевую систему.
Второе - реальная стоимость. На бумаге $5 за миллион входных токенов выглядит терпимо. В режиме агента каждая задача разворачивается в 20-50 шагов, каждый со своим контекстом. Суммарный счёт за один сложный запрос легко становится в десять раз больше, чем за одиночный вызов модели. Перед стартом нужна честная прикидка стоимости на 1000 типовых запросов, не на одном.
Третье - режимы и цены отличаются. В Codex окно памяти 400 тысяч токенов, в API - миллион. У GPT-5.5 Pro цена $30 / $180 за миллион, у обычной - $5 / $30. Для разных задач имеет смысл собирать гибрид: лёгкая модель на разбор файлов, топовая - только на финальное рассуждение. Иначе бюджет проекта проиграет до релиза.
Что дальше#
Через 6-9 месяцев на OfficeQA Pro появятся Claude следующего поколения и Gemini 4. Разрыв в режиме полного агента сократится, цифры выровняются. Заявка "первая модель >50%" короткоживущая.
Что мы будем тестировать в ближайших проектах: собрать аналог OfficeQA на 50-100 русскоязычных юридических и финансовых документах, прогнать через те модели, к которым есть доступ из РФ. Цель - получить честную табличку "точность × стоимость × задержка ответа" для конкретных корпоративных сценариев. Если соберём - выложим результаты в @digitalimpulschannel.
Источники:
- Databricks brings GPT-5.5 to enterprise agent workflows | OpenAI
- Databricks partners with OpenAI on GPT-5.5 | Databricks Blog
- OpenAI GPT-5.5 now available on Databricks | Databricks Blog
- OfficeQA Pro: An Enterprise Benchmark for End-to-End Grounded Reasoning | arXiv
- Introducing OfficeQA | Databricks Blog
- Introducing GPT-5.5 | OpenAI
- databricks/officeqa | GitHub
- Databricks releases enterprise-focused OfficeQA AI benchmark | VentureBeat
Больше разборов AI-новостей с цифрами и без хайпа - в нашем канале @digitalimpulschannel.
